Kubernetes 容器健康检查和优雅终止

在 Kubernetes 中启用容器健康检查和优雅终止,并结合应用自身特点进行配置,可以提升生产环境的应用稳定性,减少上线事故和误报。
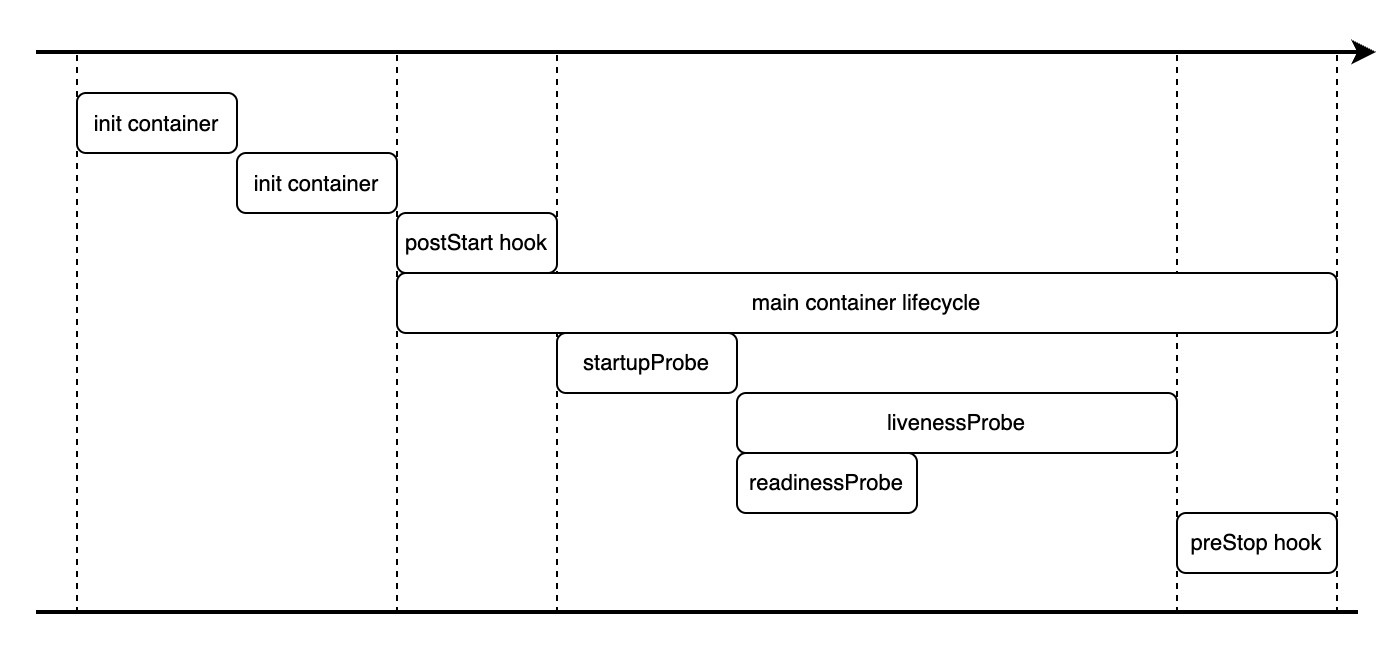
配置项
相关配置项解释如下:
terminationGracePeriodSeconds: 全局配置项,Pod 终止的宽限期,必须大于lifecycle.preStop,如果 Pod 中的容器在达到宽限期时仍未停止,Pod 将被强制终止lifecycle.preStop: 在容器停止之前执行命令的钩子,可用于推迟容器停止时间,确保容器有更多的剩余时间处理用户尚未完成的请求startupProbe: 检查容器的启动状态,可用于为容器内的应用启动提供更多的准备时间,如果检查失败,kubelet 会杀死容器,然后再次启动容器livenessProbe: 检查容器是否存活,如果检查失败,kubelet 会杀死容器,然后再次启动容器readinessProbe: 检查容器是否已经准备好接受流量,只有通过检查,kubelet 才会将 Pod 加入到 Service 的负载均衡池
实践
启用 容器健康检查 和 优雅终止 的 Kubernetes Deployment 实践配置示例:
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
# 默认值: 30
terminationGracePeriodSeconds: 120
imagePullSecrets:
- name: mysecret
containers:
- name: myapp
image: registry.example.com/myapp:1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 500m
memory: 1Gi
env:
- name: TZ
value: Asia/Shanghai
startupProbe:
tcpSocket:
port: 8080
# 默认值: 0
initialDelaySeconds: 10
# 默认值: 10
# 固定间隔, 不会等待上一次探测完成
periodSeconds: 10
# 默认值: 3
failureThreshold: 30
# 默认值: 1
# 不能更改, 工作原理决定了只能设置为 1
successThreshold: 1
# 默认值: 1
timeoutSeconds: 2
livenessProbe:
tcpSocket:
port: 8080
# 默认值: 0
initialDelaySeconds: 10
# 默认值: 10
# 固定间隔, 不会等待上一次探测完成
periodSeconds: 30
# 默认值: 3
failureThreshold: 5
# 默认值: 1
# 不能更改, 工作原理决定了只能设置为 1
successThreshold: 1
# 默认值: 1
timeoutSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
# 默认值: 0
initialDelaySeconds: 5
# 默认值: 10
# 固定间隔, 不会等待上一次探测完成
periodSeconds: 20
# 默认值: 3
failureThreshold: 3
# 默认值: 1
# 设置为 2, 避免不稳定的新容器替换正常的旧容器
successThreshold: 2
# 默认值: 1
timeoutSeconds: 2
lifecycle:
# 容器停止时间推迟 60 秒
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 60"]Kubernetes 默认配置:
- 启动:
无 - 上线:
最短:0秒
异常判定:21秒( failureThreshold(3) - 1 ) * periodSeconds(10) + timeoutSeconds(1) - 就绪:
最短:0秒
异常判定:21秒( failureThreshold(3) - 1 ) * periodSeconds(10) + timeoutSeconds(1)
恢复判定:10秒periodSeconds(10) - 终止:
最短:0秒
最长:30秒terminationGracePeriodSeconds(30)
实践配置:
- 启动:
最短:10秒initialDelaySeconds(10)
异常判定:302秒initialDelaySeconds(10) + ( failureThreshold(30) - 1 ) * periodSeconds(10) + timeoutSeconds(2)
注意: 工作原理决定了startupProbe.successThreshold只能设置为1 - 上线:
最短:20秒启动(10)+initialDelaySeconds(10)
异常判定(首次):135秒initialDelaySeconds(10) + ( failureThreshold(5) - 1 ) * periodSeconds(30) + timeoutSeconds(5)
异常判定(持续):125秒( failureThreshold(5) - 1 ) * periodSeconds(30) + timeoutSeconds(5)
注意: 工作原理决定了livenessProbe.successThreshold只能设置为1 - 就绪:
最短:35秒启动(10)+initialDelaySeconds(5) + ( readinessProbe.successThreshold(2) - 1 ) * periodSeconds(20)
异常判定(首次):47秒initialDelaySeconds(5) + ( failureThreshold(3) - 1 ) * periodSeconds(20) + timeoutSeconds(2)
异常判定(持续):42秒( failureThreshold(3) - 1 ) * periodSeconds(20) + timeoutSeconds(2)
恢复判定:40秒successThreshold(2) * periodSeconds(20) - 终止:
最短60秒sleep 60
最长120秒terminationGracePeriodSeconds(120)
与 Kubernetes 默认配置相比,以上实践配置进行了如下优化:
- 启动: 推迟
10秒,异常判定需要302秒,检查失败会重启容器 - 上线: 推迟
20秒,异常判定需要125秒,检查失败会重启容器 - 就绪: 推迟
35秒,健康检查2次,避免不稳定的新容器替换正常的旧容器,异常判定需要42秒,检查失败会阻止入站请求,恢复判定需要40秒,检查成功会允许入站请求 - 终止: 立即阻止旧容器的入站请求,推迟
60秒终止旧容器,确保旧容器有更多的剩余时间处理用户尚未完成的请求,避免用户尚未完成的请求被异常中断
优化
方案如下:
- 对于 Web 类应用,通过应用代码判断自身业务状态,生成
/healthz健康检查页面 - 将基于
tcpSocket的健康检查升级为基于httpGet,通过获取健康检查页面的返回结果进行精准判断
详细的健康检查端点 /healthz 设计请参考: 健康检查端点 /healthz 设计实践。
启用 /healthz 健康检查页面的 Kubernetes Deployment 实践配置示例:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
# 默认值: 30
terminationGracePeriodSeconds: 120
imagePullSecrets:
- name: mysecret
containers:
- name: myapp
image: registry.example.com/myapp:1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 500m
memory: 1Gi
env:
- name: TZ
value: Asia/Shanghai
startupProbe:
tcpSocket:
port: 8080
# 默认值: 0
initialDelaySeconds: 10
# 默认值: 10
# 固定间隔, 不会等待上一次探测完成
periodSeconds: 10
# 默认值: 3
failureThreshold: 30
# 默认值: 1
# 不能更改, 工作原理决定了只能设置为 1
successThreshold: 1
# 默认值: 1
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /healthz
port: 8080
# 默认值: 0
initialDelaySeconds: 10
# 默认值: 10
# 固定间隔, 不会等待上一次探测完成
periodSeconds: 30
# 默认值: 3
failureThreshold: 5
# 默认值: 1
# 不能更改, 工作原理决定了只能设置为 1
successThreshold: 1
# 默认值: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /healthz
port: 8080
# 默认值: 0
initialDelaySeconds: 5
# 默认值: 10
# 固定间隔, 不会等待上一次探测完成
periodSeconds: 20
# 默认值: 3
failureThreshold: 3
# 默认值: 1
# 设置为 2, 避免不稳定的新容器替换正常的旧容器
successThreshold: 2
# 默认值: 1
timeoutSeconds: 2
lifecycle:
# 容器停止时间推迟 60 秒
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 60"]优雅中断
容器健康检查可以确保 Pod 处于健康的运行状态,容器优雅终止可以让 Pod 延迟下线。
通常,用户的请求需要先经过 Ingress 转发,但 Ingress 可能默认不会等待 Pod 的 Terminating 状态完成,就提前将 Pod 从后端移除了,例如阿里云 Kubernetes 容器服务。
这种情况下,为了避免用户尚未完成的请求被 Ingress 异常中断,还需要在 Ingress 上配置与 lifecycle.preStop 匹配的优雅中断超时时间。
这样,在优雅中断时间结束前,Ingress 才不会主动关闭与 Pod 的连接。
阿里云 Kubernetes 优雅中断配置示例:
---
apiVersion: v1
kind: Service
metadata:
namespace: default
name: myapp-svc
spec:
selector:
app: myapp
clusterIP: None
ports:
- port: 8080
targetPort: 8080
protocol: TCP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: default
name: myapp-ingress
annotations:
# 开启优雅中断
alb.ingress.kubernetes.io/connection-drain-enabled: "true"
# 优雅中断超时时间,与 lifecycle.preStop 匹配
alb.ingress.kubernetes.io/connection-drain-timeout: "60"
spec:
ingressClassName: alb
rules:
- host: example.com
http:
paths:
- path: /myapp
pathType: Prefix
backend:
service:
name: myapp-svc
port:
number: 8080参考
https://kubernetes.io/zh-cn/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
https://help.aliyun.com/zh/ack/serverless-kubernetes/user-guide/advanced-alb-ingress-settings#c5bf22507239t