Python OpenCV CAPTCHA Recognition in Action

The recognition principles and processes I have learned from the CAPTCHA recognition are really valuable.
Background
My current company has a good learning and sharing atmosphere,sometimes holds various geek competitions, this one is about CAPTCHA recognition.
Processes
At first, I was thinking of finding some existing codes from GitHub and just modifying some parameters. Then I tried some programs that seemed to be able to train and recognize without any feature engineering, but the actual results were terrible.
During the competition, colleagues kept showing their stage results in the group, and they all did feature engineering. So I also searched the articles in this area and finally completed it successfully with a recognition rate of over 99%.
The main processes are as follows.
-
1.Collect samples
Only 100 sample CAPTCHAs were provided to all participants in this CAPTCHA recognition contest.
-
2.Feature engineering
Using the OpenCV library to analyze the CAPTCHA samples, remove the noise such as various random lines, and highlight the characters in the CAPTCHA such as 5UFQ.
-
3.Manual labeling
Manually recognize and rename each original CAPTCHA as its characters such as 5UFQ.jpg, then cut the CAPTCHAs into individual character images after feature engineering and saved as: 5UFQ_5.jpg, 5UFQ_U.jpg, 5UFQ_F.jpg, 5UFQ_Q.jpg.
-
4.Train the model
Use the above images with single characters as training set, and the characters of each image as labels, build a mapping table of images to labels.
Perform the OpenCV’s built-in KNN similarity model for Machine learning, to train a model that can recognize similar CAPTCHAs.
-
5.Recognition
Use some original CAPTCHAs samples as the test dataset, remove the noise by feature engineering, then use the trained model to recognize them and save the results in a CSV file.
Details
1. Collect samples
To prevent people from using the existing codes on the Internet and counting the results out by violence, only 100 image samples were provided to all participants.
In practice, a lot more CAPTCHAs samples should be collected.

2. Feature engineering
Use the CAPTCHA with characters of 5UFQ as an example.
Import the libraries.
import os
import numpy as np
from matplotlib import pyplot as plt
import cv2Read and display the original sample.
filepath='imgs/train/5UFQ.jpg'
im=cv2.imread(filepath)
plt.imshow(im[:,:,[2,1,0]])
plt.show()
Convert the image from RGB to grayscale, to remove the color information.
# convert the image from BGR into gray
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
plt.imshow(im_gray,cmap="gray")
plt.show()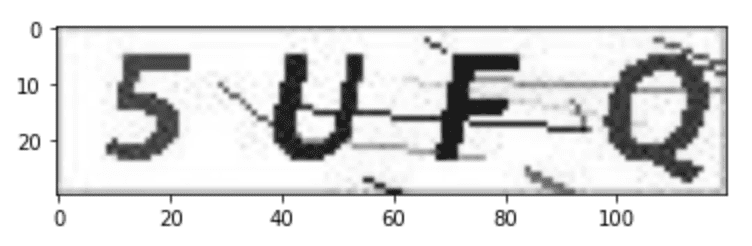
Binarize the image to give a distinct black-and-white effect.
# image binarization, the default threshold is 127
ret, im_inv = cv2.threshold(im_gray,127,255,cv2.THRESH_BINARY_INV)
plt.imshow(im_inv,cmap="gray")
plt.show()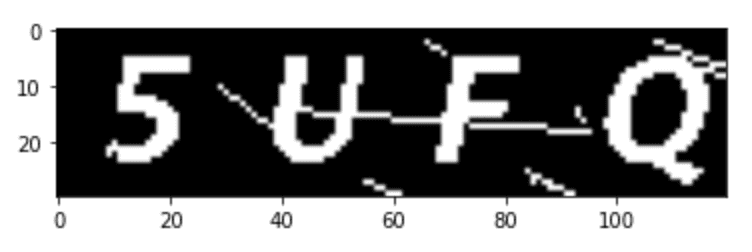
Use the Gaussian Blur to reduce noise and details, with the visual effect of looking at the image through a translucent frosted screen.
# image denoising using the gaussian blur
kernel = 1/16*np.array([[1,2,1], [2,4,2], [1,2,1]])
im_blur = cv2.filter2D(im_inv,-1,kernel)
plt.imshow(im_blur,cmap="gray")
plt.show()
Then Binarize again to eliminate the noise such as streaks
# image binarization, after debugging, found that 185 is a better value for the blurred CAPTCHAs
ret, im_res = cv2.threshold(im_blur,185,255,cv2.THRESH_BINARY)
plt.imshow(im_res,cmap="gray")
plt.show() 
3. Manual labeling
Manually identify each original sample and rename it as the characters.

By looking at all the sample CAPTCHA images, it is easy to see that each character is in a very consistent area in the image, which greatly reduces the difficulty of determining the character regions and cutting the images.
# after debugging, found that all CAPTCHAs characters are same size and positions are quite fit
# so just find out the position values of each CAPTCHA character and get the images data
roi_dict[0] = im_res[4:25, 8:28]
roi_dict[1] = im_res[4:25, 38:58]
roi_dict[2] = im_res[4:25, 68:88]
roi_dict[3] = im_res[4:25, 98:118]
# return all CAPTCHAs characters as a dictionary
return roi_dictCut images that have been feature engineered into individual character images.
def cut_img(train_dir,cut_dir,suffix):
# walk through the directory
for root,dirs,files in os.walk(train_dir):
for f in files:
# get the file path
filepath = os.path.join(root,f)
# check the file suffix
filesuffix = os.path.splitext(filepath)[1][1:]
if filesuffix in suffix:
# get the images data of each CAPTCHA character
roi_dict = fix_img(filepath)
# cut each CAPTCHA character with the filename incluing the label
for i in sorted(roi_dict.keys()):
cv2.imwrite("{0}/{1}_{2}.jpg".format(cut_dir,f.split('.')[0],f[i]),roi_dict[i])
# close cv2 write operation
cv2.waitKey(0)
return True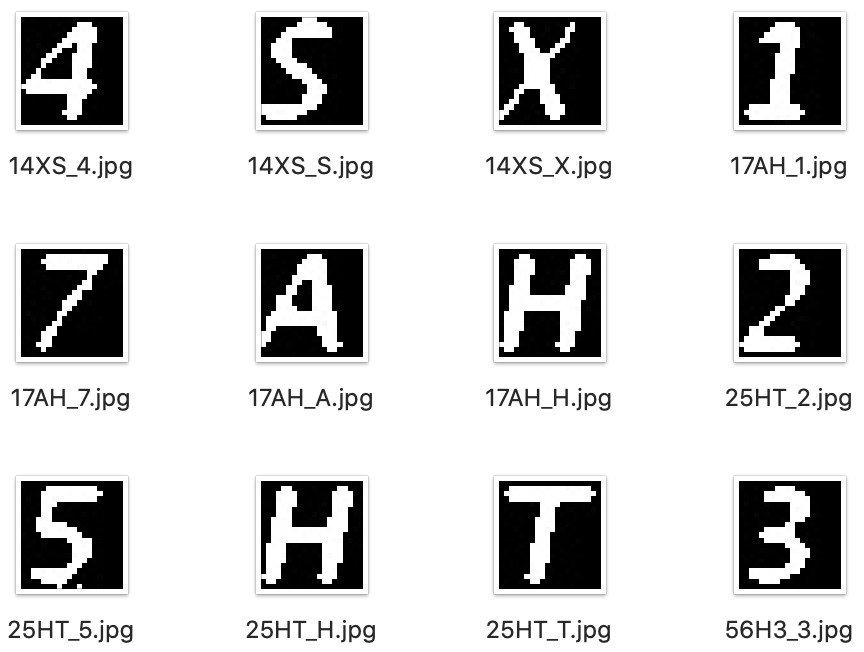
4. Train the model
Perform the OpenCV’s built-in KNN similarity model to train a model that can recognize similar CAPTCHAs.
def train_model(cut_dir,suffix):
# create an empty dataset to store the information of CAPTCHAs characters
samples = np.empty((0, 420))
# create an empty lables list
labels = []
# walk through the directory
for root,dirs,files in os.walk(cut_dir):
for f in files:
filepath = os.path.join(root,f)
filesuffix = os.path.splitext(filepath)[1][1:]
if filesuffix in suffix:
filepath = os.path.join(root,f)
# read the label of each CAPTCHA character
label = f.split(".")[0].split("_")[-1]
labels.append(label)
# store the CAPTCHA character data into samples dataset
im = cv2.imread(filepath, cv2.IMREAD_GRAYSCALE)
sample = im.reshape((1, 420)).astype(np.float32)
samples = np.append(samples, sample, 0)
samples = samples.astype(np.float32)
# labels-label_id mapping
unique_labels = list(set(labels))
unique_ids = list(range(len(unique_labels)))
label_id_map = dict(zip(unique_labels, unique_ids))
id_label_map = dict(zip(unique_ids, unique_labels))
label_ids = list(map(lambda x: label_id_map[x], labels))
label_ids = np.array(label_ids).reshape((-1, 1)).astype(np.float32)
# train the model with KNN
model = cv2.ml.KNearest_create()
model.train(samples, cv2.ml.ROW_SAMPLE, label_ids)
# return the model and labels-label_id mapping
return {'model':model,'id_label_map':id_label_map}5. Recognition
Load test dataset, remove the noise by feature engineering, then use the trained model to recognize CAPTCHAs and save the results in a CSV file.
def rek_img(model_dict,rek_dir,suffix,results_csv):
# get the model and labels-label_id mapping
model = model_dict['model']
id_label_map = model_dict['id_label_map']
label_dict = {}
# walk through the directory
for root,dirs,files in os.walk(rek_dir):
for f in files:
filepath = os.path.join(root,f)
filesuffix = os.path.splitext(filepath)[1][1:]
if filesuffix in suffix:
# get the images data of each CAPTCHA character
roi_dict = fix_img(filepath)
# get the value of each CAPTCHA character from the model
for i in sorted(roi_dict.keys()):
sample = roi_dict[i].reshape((1, 420)).astype(np.float32)
ret, results, neighbours, distances = model.findNearest(sample, k = 3)
label_id = int(results[0,0])
label = id_label_map[label_id]
label_dict[i] = label
# convert all CAPTCHA characters values into a string
result_str = ''.join(str(v) for k,v in sorted(label_dict.items()))
# append the result into a csv
with open(results_csv, "a") as myfile:
myfile.write("{0},{1}\n".format(f,result_str))
myfile.close()
return True
Summary
The CAPTCHA images in this competition were more distinctive and easier to feature engineer, so in the end, although 10k CAPTCHA images were used as the test set, many colleagues still achieved recognition accuracy of over 90%, and the winner’s accuracy even reached an incredible 100%.
For me, the recognition principles and processes I have learned from the CAPTCHA recognition are really valuable.
References
Source code: captchas-opencv-rek
Inspired by: https://www.cnblogs.com/lizm166/p/9969647.html