Kubernetes Container Healthcheck and Graceful Termination

Kubernetes container health checks and graceful termination enhances production stability, reduces deployment incidents and false alarms.
Parameters
terminationGracePeriodSeconds: Global setting for Pod termination grace period, must greater thanlifecycle.preStop. If containers aren’t stopped within this period, the Pod will be forcibly terminated.lifecycle.preStop: Hook to execute commands before container stops, delaying termination to release connections for in-flight requests.startupProbe: Checks the container startup status, providing additional preparation time. kubelet kills and restarts the container if the check fails.livenessProbe: Checks if the container is alive. kubelet kills and restarts the container if the check fails.readinessProbe: Checks if the container is ready to accept traffic. kubelet adds the Pod to the Service’s load balancer pool only if this check passes.
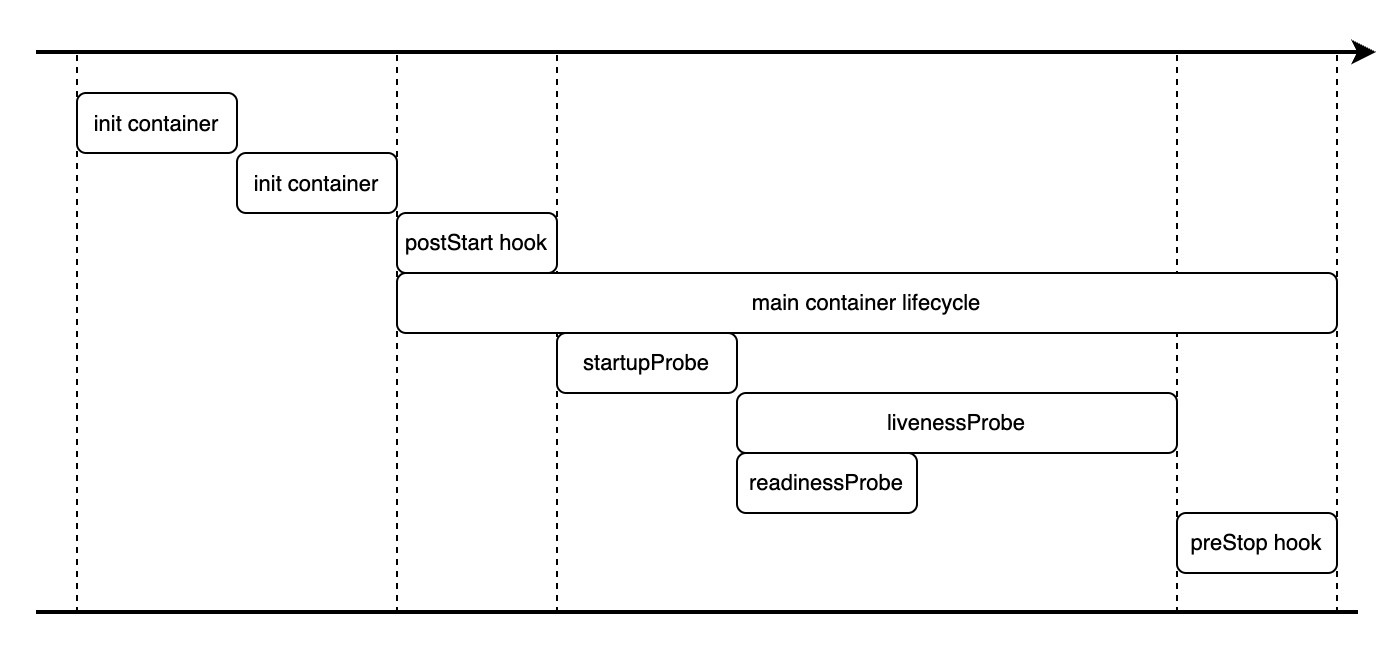
Practice
Kubernetes deployment configurations with health checks and graceful termination:
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: default
name: myapp
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
# default: 30
terminationGracePeriodSeconds: 120
imagePullSecrets:
- name: mysecret
containers:
- name: myapp
image: registry.example.com/myapp:1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 500m
memory: 1Gi
env:
- name: TZ
value: Asia/Shanghai
startupProbe:
tcpSocket:
port: 8080
# default: 0
initialDelaySeconds: 10
# default: 10
# fixed interval, does not wait for the previous probe to complete
periodSeconds: 10
# default: 3
failureThreshold: 30
# default: 1
# cannot be changed, must be 1 by design
successThreshold: 1
# default: 1
timeoutSeconds: 2
livenessProbe:
tcpSocket:
port: 8080
# default: 0
initialDelaySeconds: 10
# default: 10
# fixed interval, does not wait for the previous probe to complete
periodSeconds: 30
# default: 3
failureThreshold: 5
# default: 1
# cannot be changed, must be 1 by design
successThreshold: 1
# default: 1
timeoutSeconds: 5
readinessProbe:
tcpSocket:
port: 8080
# default: 0
initialDelaySeconds: 5
# default: 10
# fixed interval, does not wait for the previous probe to complete
periodSeconds: 20
# default: 3
failureThreshold: 3
# default: 1
# set to 2 to avoid mistaking unstable new containers as ready
successThreshold: 2
# default: 1
timeoutSeconds: 2
lifecycle:
# delay container stop by 60 seconds
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 60"]Default Kubernetes configurations:
- Startup Check:
None - Liveness:
Minimum:0seconds
Failure determination:21seconds( failureThreshold(3) - 1 ) * periodSeconds(10) + timeoutSeconds(1) - Readiness:
Minimum:0seconds
Failure determination:21seconds( failureThreshold(3) - 1 ) * periodSeconds(10) + timeoutSeconds(1)
Recovery determination:10secondsperiodSeconds(10) - Termination:
Minimum:0seconds
Maximum:30secondsterminationGracePeriodSeconds(30)
Practice configurations:
- Startup:
Minimum:10secondsinitialDelaySeconds(10)
Failure determination:302secondsinitialDelaySeconds(10) + ( failureThreshold(30) - 1 ) * periodSeconds(10) + timeoutSeconds(2)
Note: The working principle determines thatstartupProbe.successThresholdcan only be set to1 - Liveness:
Minimum:20secondsStartup(10)+initialDelaySeconds(10)
Failure determination (first):135secondsinitialDelaySeconds(10) + ( failureThreshold(5) - 1 ) * periodSeconds(30) + timeoutSeconds(5)
Failure determination (running):125seconds( failureThreshold(5) - 1 ) * periodSeconds(30) + timeoutSeconds(5)
Note: The working principle determines thatlivenessProbe.successThresholdcan only be set to1 - Readiness:
Minimum:35secondsStartup(10)+initialDelaySeconds(5) + ( readinessProbe.successThreshold(2) - 1 ) * periodSeconds(20)
Failure determination (first):47secondsinitialDelaySeconds(5) + ( failureThreshold(3) - 1 ) * periodSeconds(20) + timeoutSeconds(2)
Failure determination (running):42seconds( failureThreshold(3) - 1 ) * periodSeconds(20) + timeoutSeconds(2)
Recovery determination:40secondssuccessThreshold(2) * periodSeconds(20) - Termination:
Minimum60secondssleep 60
Maximum120secondsterminationGracePeriodSeconds(120)
Optimizations compared to default Kubernetes configurations:
- Startup:
10seconds delay, failure threshold302seconds, failed checks trigger container restart. - Liveness:
20seconds delay, failure threshold125seconds, failed checks trigger container restart. - Readiness:
35seconds delay,2times health checks to avoid mistaking unstable new containers as ready, failure threshold42seconds blocks inbound traffic,40seconds recovery threshold allows inbound traffic again. - Termination: Immediately block inbound traffic to old container, allow
60seconds delay before termination to ensure in-flight user requests complete gracefully.
Optimization
Solution:
- Create a
/healthzendpoint for accurate health checks. - Upgrade from
tcpSockettohttpGethealth checks for precise assessments.
For more detailed health check endpoint /healthz design, please refer to the article: Health Check Endpoint /healthz Design Practice.
Kubernetes deployment configurations enables the /healthz endpoint:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: myapp
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
# default: 30
terminationGracePeriodSeconds: 120
imagePullSecrets:
- name: mysecret
containers:
- name: myapp
image: registry.example.com/myapp:1.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 500m
memory: 1Gi
env:
- name: TZ
value: Asia/Shanghai
startupProbe:
tcpSocket:
port: 8080
# default: 0
initialDelaySeconds: 10
# default: 10
# fixed interval, does not wait for the previous probe to complete
periodSeconds: 10
# default: 3
failureThreshold: 30
# default: 1
# cannot be changed, must be 1 by design
successThreshold: 1
# default: 1
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /healthz
port: 8080
# default: 0
initialDelaySeconds: 10
# default: 10
# fixed interval, does not wait for the previous probe to complete
periodSeconds: 30
# default: 3
failureThreshold: 5
# default: 1
# cannot be changed, must be 1 by design
successThreshold: 1
# default: 1
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /healthz
port: 8080
# default: 0
initialDelaySeconds: 5
# default: 10
# fixed interval, does not wait for the previous probe to complete
periodSeconds: 20
# default: 3
failureThreshold: 3
# default: 1
# set to 2 to avoid mistaking unstable new containers as ready
successThreshold: 2
# default: 1
timeoutSeconds: 2
lifecycle:
# delay container stop by 60 seconds
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 60"]Graceful Draining
Container health checks ensure that Pods are running properly, while graceful termination allows Pods to delay shutdown.
Typically, user requests are routed through an Ingress. However, some Ingress controllers such as Alibaba Cloud Kubernetes may remove Pods from backend pools before the Pod fully Terminated.
To avoid interrupting in-flight user requests, the Ingress should be configured with a graceful connection drain timeout that aligns with the container lifecycle.preStop.
This ensures the Ingress keeps connections alive until the timeout expires.
Alibaba Cloud Kubernetes graceful draining configuration:
---
apiVersion: v1
kind: Service
metadata:
namespace: default
name: myapp-svc
spec:
selector:
app: myapp
clusterIP: None
ports:
- port: 8080
targetPort: 8080
protocol: TCP
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: default
name: myapp-ingress
annotations:
# enable graceful draining
alb.ingress.kubernetes.io/connection-drain-enabled: "true"
# match lifecycle.preStop
alb.ingress.kubernetes.io/connection-drain-timeout: "60"
spec:
ingressClassName: alb
rules:
- host: example.com
http:
paths:
- path: /myapp
pathType: Prefix
backend:
service:
name: myapp-svc
port:
number: 8080Reference
https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
https://help.aliyun.com/zh/ack/serverless-kubernetes/user-guide/advanced-alb-ingress-settings#c5bf22507239t